Resolution is based on the chatbot arena LLM leaderboard (https://lmarena.ai), specifically the company with the highest Arena Score in the Overall category, without style control or show deprecated, at the end of August 31st, 2025 11:59PM ET.
In the case of a tie, all companies tied for 1st place resolve to equal probability, such that they sum to 100%.
See also:
/Bayesian/which-company-has-the-best-ai-model
/Bayesian/who-will-have-the-best-texttoimage-SO0uN6suuS
/Bayesian/who-will-have-the-best-texttovideo-AtZ0CdIc8Z
/Bayesian/which-company-has-best-ai-computer
/Bayesian/which-company-has-best-vision-ai-en
/Bayesian/which-company-has-best-search-ai-mo
Previous months:
/Bayesian/which-company-has-best-ai-model-end
/Bayesian/which-company-has-best-ai-model-end-I0QsydsZuz
/Bayesian/which-company-has-best-ai-model-end-0CRdhqptRl
 1,000
1,000 3.00
3.00
@realDonaldTrump it's explained by the pinned message. if you go on the top right of the text leaderboard and select "without style control", you'll get the correct ordering for the purpose of this market

One interesting thing is head-to-head (with style control), GPT-5 losses to Gemini 2.5 about ~66% of the time, which is significant (p<0.05). GPT-5 beats out some other models at a bit higher rate, but not by much. For example, if we look at the rate GPT-5 beats Claude-Sonnet-4-thinking (0.74 with 47 samples) and the rate rate Gemini2.5 beats than Claude-Sonnet-4-thiniing (0.68 with 330 samples), we can note GPT-5 rate is not significantly greater than the Gemini2.5 rate (Fischer exact test p ~= 0.24).
The 21 point ELO with lead style control seems tenuous, and then are tied in ELO without style control. With more data, Gemini could take the lead there.
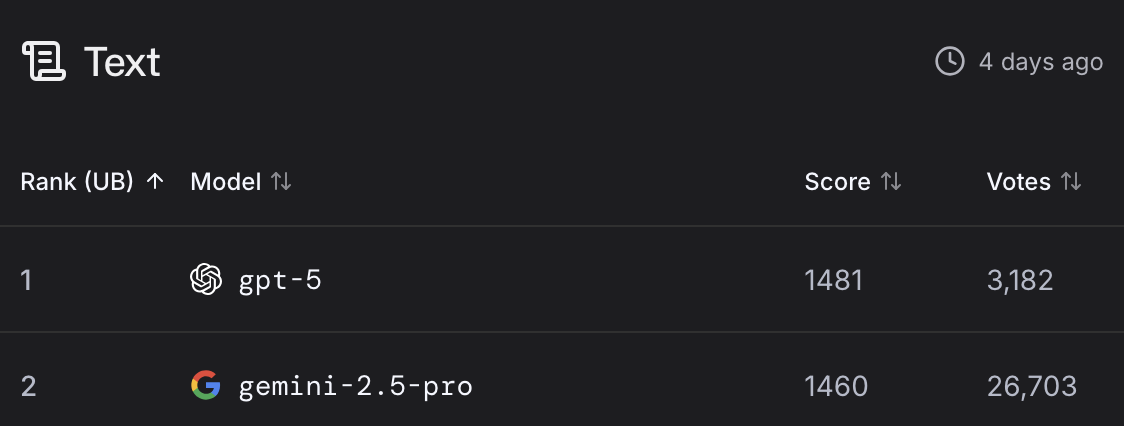
@sblaplace No, you can have the same ranking but different arena score, and ties refer to arena score ties only
@Bayesian yah it's my reading failure, and for some reason I thought we had all migrated to just whatever the leaderboard says at the end of the month